How Machine Learning Can Improve Surf Forecasts
I’d like to share with you what I believe are the three biggest problems with the various surf forecast/report services that are currently available, and why I think machine learning is well suited to address these problems. Ultimately, it’s my view that a surf forecasting service driven by machine learning has the potential to provide more affordable, accurate forecasts to users in a way that better aligns with the values of surf culture.
Without wasting any time, let’s dive in and start with the first and most obvious problem. Please note that for the sake of brevity, when I say ‘surf forecast’ I’m talking about both ‘surf forecasts’, which are made in advance, and ‘surf reports’, which describe the current conditions.
Problem 1: Surf Forecasts are not Always Accurate
Let me give an example. The following two images show day 0 forecast for a surf break in Wellington, NZ along with the actual observed conditions that day.
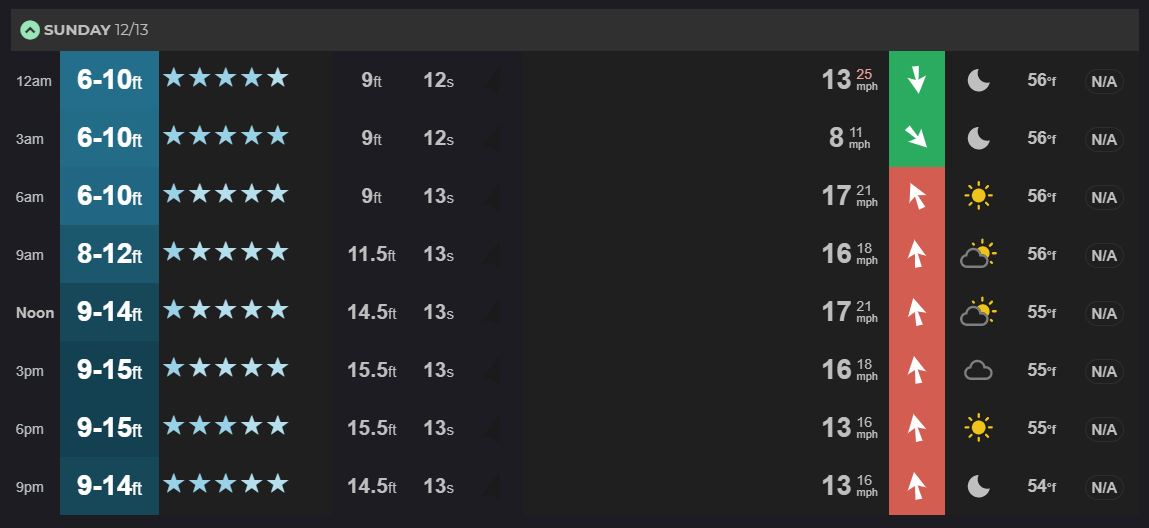

The photo on the bottom was taken at around the time when the forecast was predicting 9-15 ft waves. Assuming the surfer is around 6 ft tall we can estimate the waves to be about 4-5 ft maximum. That’s quite a poor forecast. To understand why this forecast was so innaccurate (and to get some ideas about how we can improve it), we need to first understand how it was made.
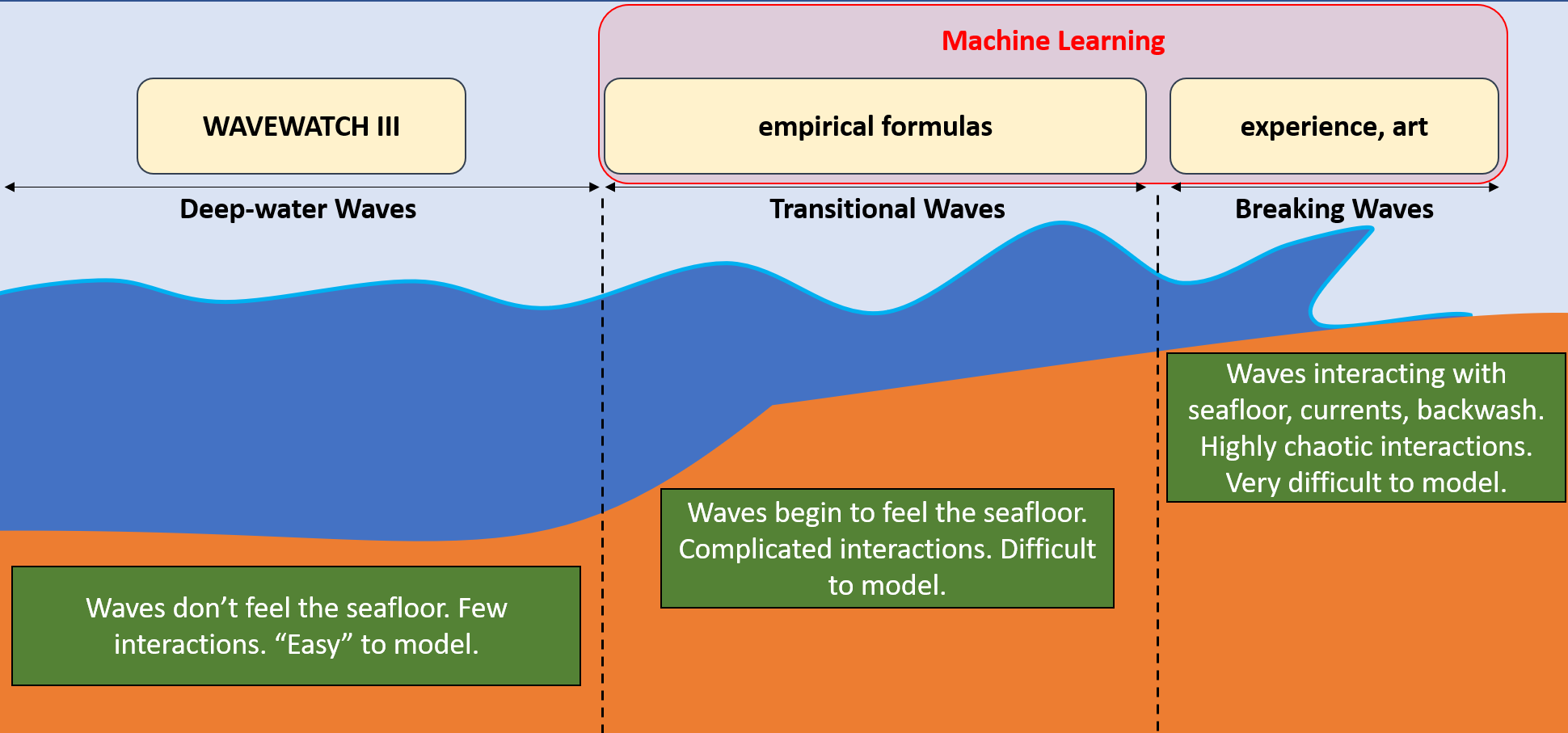
As far as I know, every surf forecast provider’s first step in making a forecast begins the same: with wave predictions from NOAA’s WAVEWATCH III (WW3) model. WW3 is a publicly available global wind-wave model that predicts various conditions of the ocean, including significant wave heights and wave period. It works by taking the current conditions of the sea from buoy and satellite observations and ‘forcing’ those inputs using wind estimates from a different model by solving all the underlying physical equations. Because it makes predictions by taking into account the actual physics of the ocean, WW3 is what’s known as a dynamical model. Below I’ve given an example of what the output of the WW3 model looks like.
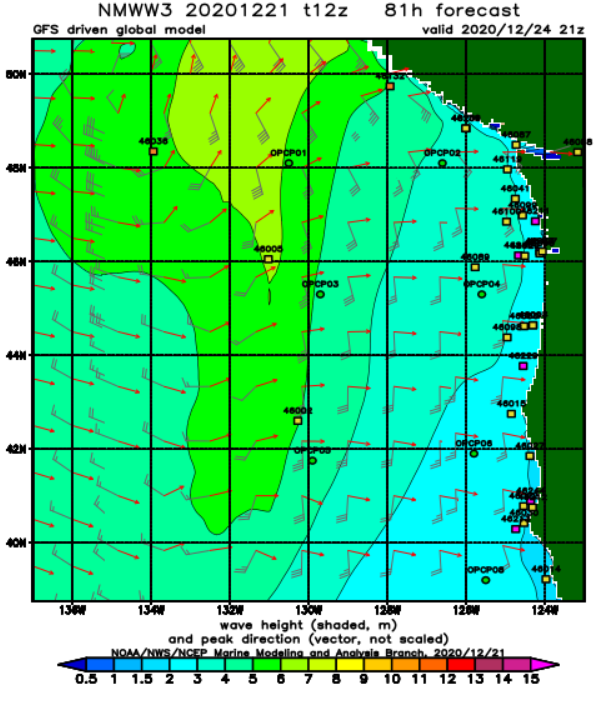
Given that WW3 predicts things like wave height and swell direction, you may be wondering why it can’t be directly used to predict how the waves will be at your local surf spot. Why pay for a premium surf forecasting service when you can simply use the freely available WW3 model? The catch here is that WW3 predicts the characteristics of waves well offshore in deep water. Such ‘deep-water waves’ are quite different from the near-shore waves that surfers ride. As a deep-water wave aproaches the shore, it begins to transform due to a variety of complicated interactions with the sea floor. Factors such as the shape of the coast, how steep the sea floor is, and whether the ocean bottom is sand or hard coral are just a few of the critical factors that determine how a deep sea wave transforms into a near-shore breaking wave. While WW3 does a great job of predicting deep-water wave characteristics, the complicated, highly nonlinear interactions in the surf zone described above are still not well enough understood to provide reliable operational estimates of breaking wave heights.
This means surf forecast services need a way of transforming WAVEWATCH III’s deep-water wave predictions into estimates of breaking waves near the shore. Each service has their own method, and I can’t give specifics since they’re all proprietary. There’s plenty of resources out there that can give you an idea of what the common approaches probably look like. From what I’ve found, it looks like beach slope, tide, angle of beach, etc. are all boiled down to likely a few simple equations, or possibly even one or two. In a way, this means forecasting breaking wave heights from deep-water waves is more of an art than an exact science, as knowledge of specific breaks is crucial to forming predictions.
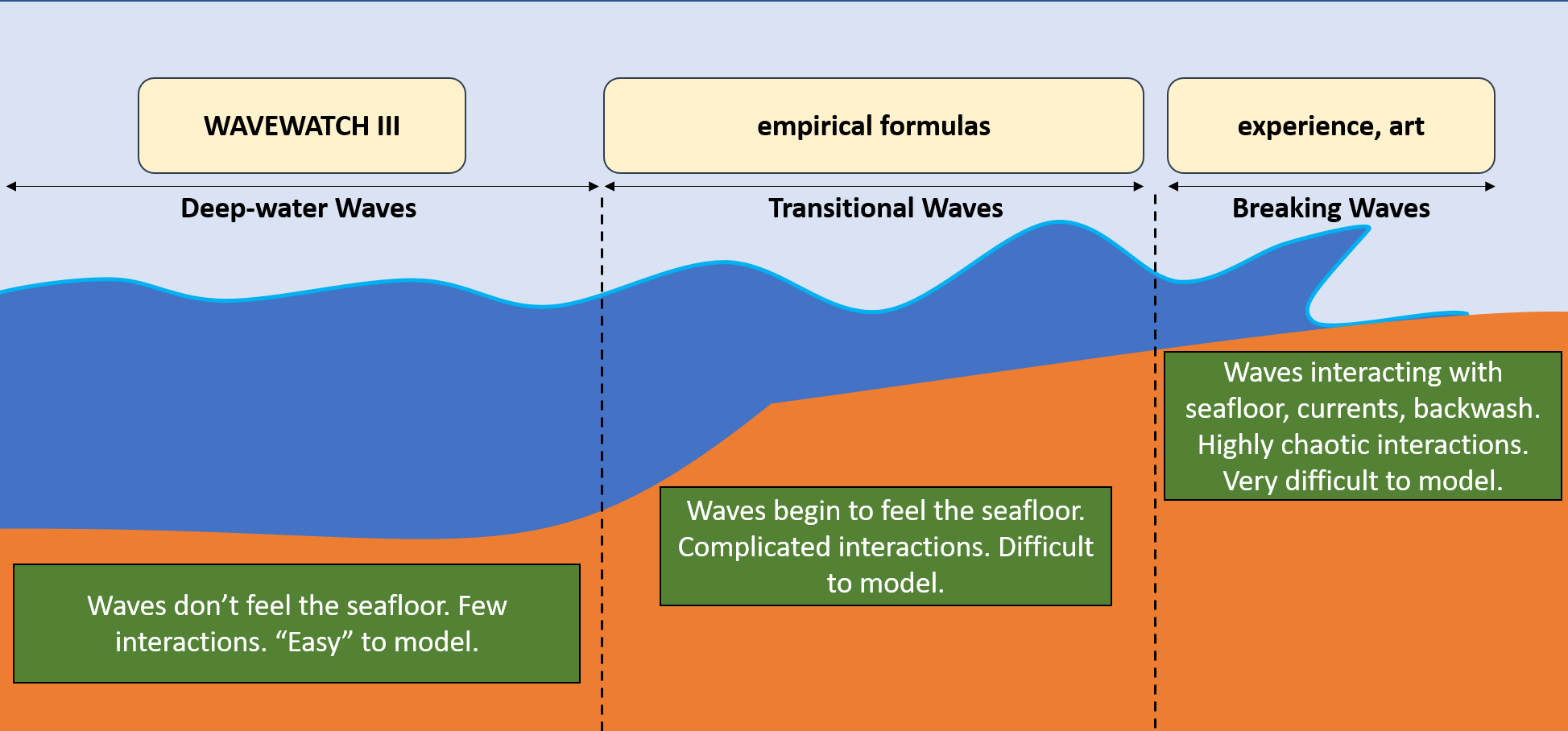
Depending on the amount of near-shore data available and how much knowledge the forecaster has of the surf spot, you’re left with forecasts that vary in their degrees of accuracy. Think back to the example I gave above in New Zealand. The forecast provider I referenced is US based, and as such probably doesn’t put a lot of effort into New Zealand surf forecasts. It’s likely that the forecaster simply chose to use to deep-water predictions from WW3 without any further corrections due to near-shore effects, which is why the forecast is so innacurate. For this reason, it’s a bit unfair of me to use this as an example. But despite being an extreme case, it’s still instructive.
This is because even predicitons made in regions where forecasters do focus their attention are susceptible to error. Take Southern California for example. Probably the most accessible spot for surfing on Earth, with over 100 breaks in San Diego County alone. Despite being relatively close to one another, each break has unique characteristics that lead to different types of waves. La Jolla shores is a sandy beach break, while just a couple miles down the road Windansea is a reef break. If a surf forecasting method doesn’t take these differences into account when transforming deep-water wave predicitons from WW3, it will end up ignoring the fact that reefs typically produce better surfing waves on long period, while beach breaks do better with mid period waves, yet typically closeout on long period swell. This potentially leads to the two locations getting the same forecast when in reality their conditions are quite different. And that’s only one of the countless other factors that are at play.
So what’s stopping someone from simply making a better model that accounts for these complex near-shore interactions?
This leads us to problem two…
Problem #2: Making Accurate Surf Forecasts is Expensive (both computationally and financially)
There are three obvious routes to improving surf forecasts:
- make a better model
- forget the models and simply put cameras everywhere
- employ experts who can use model output to make detailed forecasts
Regarding option 1: it’s not that scientists don’t know how to make better models. Indeed, there are plenty of near-shore wave models such as the SWAN Model. The issue is that these models are computationally expensive. It takes a lot of computer power to solve all the shallow water physical interactions at a resolution that’s sufficient to give good surf forecasts.
Option 2 is already implemented by many forecast services. Surfline has plenty of cameras set up in the more popular surf spots which users can view online at any time (after paying a membership fee, of course). This certainly improves the problem of giving an accurate surf report (although it does nothing to improve forecasts), but comes with its own suite of issues including angry locals who want to keep their spot secret (more on this later), and the fact that maintaining the necessary infrastructure for hundreds of cameras along the coast is expensive.
Option 3 is also utilized by various forecast services. Surfline has a team of 12 forecasters that make predictions for surf in various locations. The issue here is one of scale. To give an analogy, think back to a weather forecast that you might have seen on the local news. You probably heard phrases like ‘there’s an 80% chance of strong thunderstorms for the Atlanta metropolitan area today, with a high risk of strong winds greater than 50 mph and hail, and possibly a tornado.’ Notice that the scale of this forecast is for the entire city. The forecaster isn’t telling each individual citizen what the weather will be like in their backyard. Furthermore, the forecast doesn’t specify the exact strength of the winds, but rather gives a probability that certain strength of winds could occur (high risk of winds greater than 50 mph). It’s simply too computationally expensive (if not outright impossible) and time consuming for the forecaster to give each individual resident of the city a prediction of what the weather will be like in their own backyard.
Surf forecasting can be thought of in a similar way. Swell events affect entire regions and a general forecast is given for stretches of the coast in said regions (e.g., 3-4 ft waves in the San Diego region). But surfers need (or want) more specifics, and they want them for each individual surf spot. In essence, surfers want to know what the weather will be like in their backyard. When we recall that there are over 100 surf breaks in San Diego alone, we can begin to see why getting a detailed surf forecast/report for each individual break is impossible. While it’s true that some breaks behave very similarly, it would still require many more forecasters than there currently are to get the level of accuracy and coverage that surfers want. Such a business model isn’t even financially sustainable.
And what if it were? What if some billionaire like Jeff Bezos was an avid surfer and paid 100 forecasters every day to each make a detailed forecast for all 100+ breaks in San Diego County? Would this actually be a good thing? To answer this question, we need to talk about issue number three.
Problem #3: Forecasting Services Need to Better Consider Surf Culture
There are a lot of ways one could describe surf culture, but in my opinion there are three characteristics which are shared by almost all surfers:
- They value exploration and discovery. It’s considered poor etiquette to tell the whole world about certain high quality surf spots. Rather, it’s up to each surfer to discover such spots on their own by putting in the time and effort to gain the appropriate experience and knowledge.
- They’re protective of their local surf breaks. This topic could be a blog post on its own. For better or worse, surfers don’t like when their favorite spot is swarmed by lots of new surfers that don’t know or respect the rules of the break.
- They care about protecting the Earth’s oceans. Surfers recognize that the oceans are the source of their favourite hobby, and as such, they desperately want to keep them clean and safe.
The current business model of surf forecasting flies contrary to these three core values. For example, a map showing every surf break in San Diego, each with its own rating and detailed report, blasted out to the whole world is in my opinion, the antithesis of surf culture.
The whole situation is certainly a conundrum. Surfers want better forecasts, but better forecasts for them means better forecasts for everyone, which means more people in the water and thus more competition for the best waves. Perhaps even more insidious is the fact that such a service deprives new surfers of the valuable experienced gained by discovering new breaks for themselves and identifying under what conditions each break works best. This learning period is vital to building a sense of respect for the oceans and for their fellow surfers who have gone through a similar process.
When a new surfer is able to skip this learning phase and instead simply open up google and find the best surf spot in the region and drive out on a ‘five-star’ day, they will inevitably lack the appreciation and respect for the surf break and for the other surfers there. Further, they’re given the impression that surfing is easy, when in fact it requires a painfully long learning period that can literally span a lifetime. If aspiring surfers are led to underestimate the level of committment required to learn how to surf due to the accessible nature of surf forecasts, they are likely to give up within the first several attempts after buying a new board. Considering the environmental cost of surfboard production, we should be ensuring that purchases are made with clear eyes. Without careful consideration of the message being sent when delivering surf forecasts, we risk creating a generation of surfers who view the ocean as a commodity to be exploited for their pleasure rather than a sensitive ecosystem to be protected.
For this reason, any improvements in surf forecasting should come with the added responsibility of providing them in a way which stays true to the core values of surf culture and helps to create educated and responsible surfers.
Improving Surf Forecasts with Machine Learning
So with these three issues in mind, I began wondering what a better forecast/report system would look like. One in which the forecasts are more accurate, more affordable, and also protect the core values of surf culture.
This led me to the idea for SurfSense, an app which uses machine learning to make individualized surf forecasts and reports in the San Diego area. A machine learning model is kind of like any other model in that it uses information to make predictions. The difference is in how that prediction is made. Recall that WAVEWATCH III is a dynamical model, which means it predicts the state of the ocean by solving the governing physical equations. Machine learning models don’t try to solve the non-linear physical equations like dynamical models, but rather find patterns by analyzing a ‘training dataset’ and then use that knowledge to make future predictions.
What does this process look like in the context of SurfSense? Each time a surfer finishes a session, they submit a ‘report card’ in which they rate how good the waves were that day (e.g., ‘waves were clean and head high’). This report card is then saved into the training dataset as a label. At the same time, SurfSense automatically collects all the other important information which led to the waves being the way they were that day. This includes things like buoy observations of swell, period direction, tide, winds, and yes, WW3 model deep-water forecasts. This information is saved as the features of the training dataset.
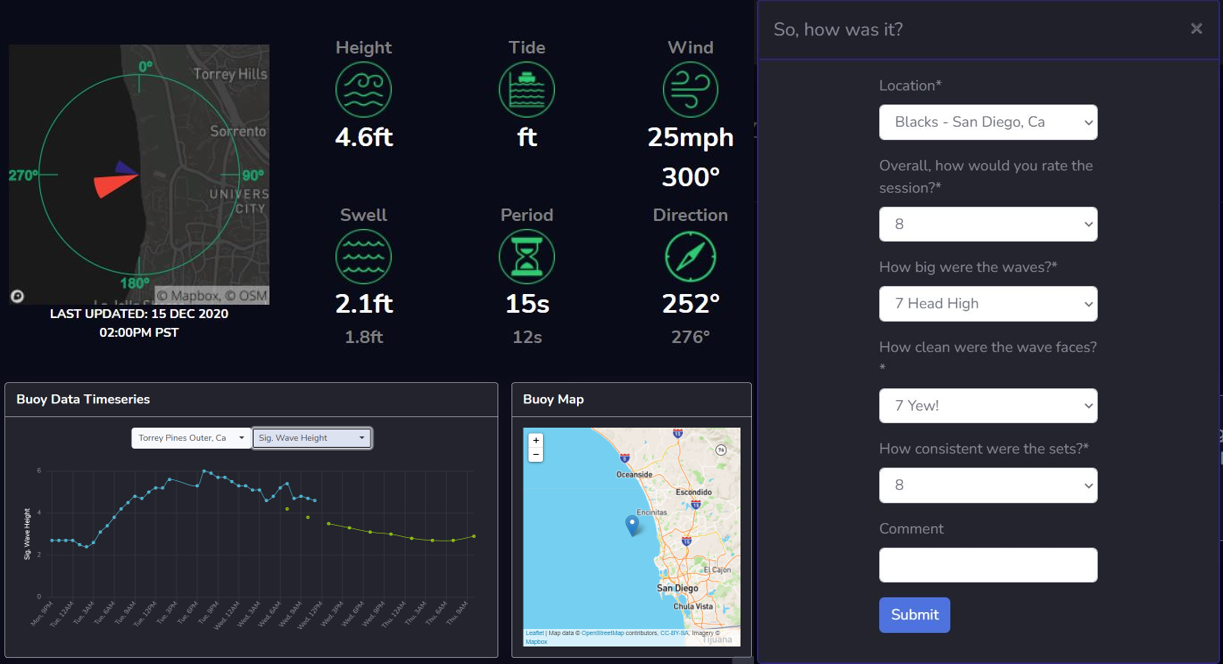
The model is then taught to find patterns between the labels and features of the training dataset. The end result is a model that makes surf forecasts by transforming WW3 predictions of deep-water waves into surf-zone breaking waves. This type of model has the potential to be more financially affordable than existing methods, as it ideally removes the need for a team of paid forecasters or an army of cameras along the coast. Furthermore, the computational cost is lowered by removing the need for high resolution dynamical models that solve the complex physical equations that govern near-shore waves.
It’s important to understand that each individual user of SurfSense will have their own training dataset based on their own surf reports. No data is shared between users. As a result, each surfer has their own personal wave model.
This is beneficial for a few reasons. First, by building a model based on individual user ratings, we ensure that each user knows exactly what to expect when SurfSense provides them with a forecast. Some surfers prefer gentle, slow waves, while others prefer hollow, barrelling waves. A longboarder’s ‘4 star rating’ may be different from a shortboarder’s ‘4 star rating’. By keeping the user’s training datasets separate, we end up with a model that speaks in their language, offering a higher degree of personalization. Perhaps more importantly, this system encourages surfers to have a more healthy relationship with the ocean by making a direct connection between model accuracy and the amount of energy and time spent by the surfer surfing. In this way, SurfSense is meant to help surfers make the most of the experience gained during each surf session, ultimately making an accurate model while also enhancing their own understanding, or sense, of the break; hence the name SurfSense.
The final question is if this will actually lead to better forecasts. The key here will be in the specifics of the machine learning model used in SurfSense. Domain knowledge of surf forecasting methods and understanding of machine learning is crucial to developing an optimal approach. For example, it’s generally accepted that machine learning models require massive training datasets numbering tens to hundreds of thousands of instances in order to be accurate. As much as they’d prefer, it’s simply not possible for surfers to surf hundreds of thousands of times. But using some knowledge of the physical interactions of the ocean along with an understanding of the various machine learning approaches, it’s actually possible to create a useful model that does not require massive amounts of training data. Rather, it may be possible that a reasonable model could be trained after only one season of surfing (which is certainly shorter than how long it takes to even learn how to surf).
For now, SurfSense is still in development. As of this writing, I’ve built an API that collects buoy observations, WW3 predictions, and relevant atmospheric conditions. It also allows you to save your surf session ratings and compares the conditions of previous sessions to present buoy and model data. In the coming months I’ll be working to include the machine learning prototype and begin testing. If you’d like to track my progress or simply take a peak at the UI, you can try out SurfSense for free by clicking here.